问题描述
这两天,在测试环境(全部为虚拟机)上搭建 K8S 的日志归集服务 EFK ( ElasticSearch + Fluend + Kibana ),在搭建完成以后,在 Kibana 中访问总是报错 Request Timeout after 3000ms,如下图:
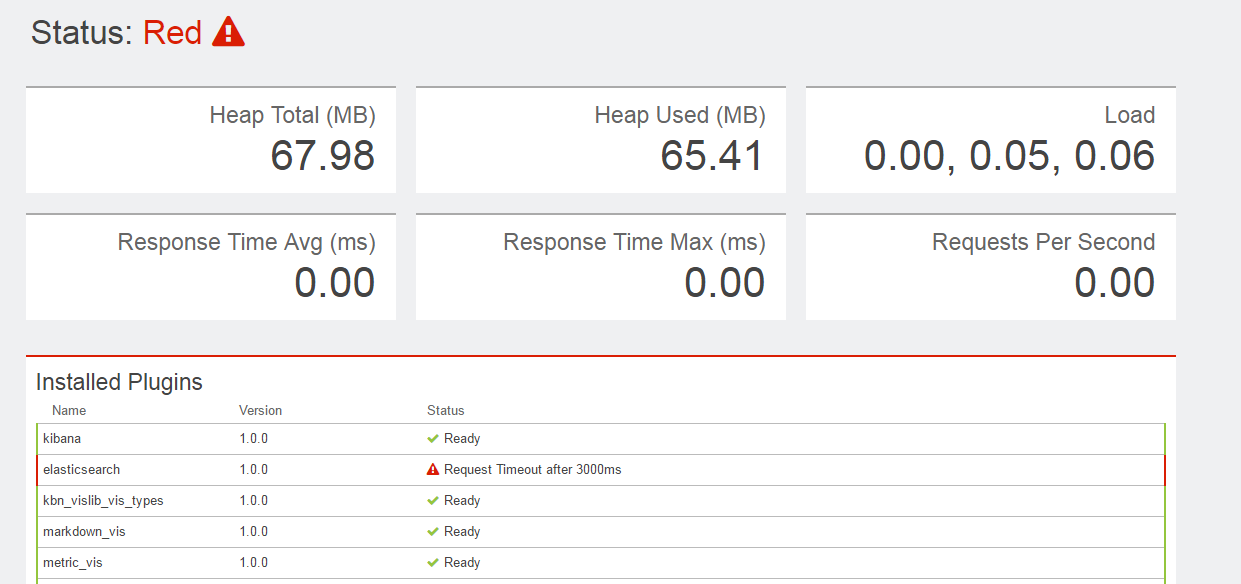
而我用相同的配置已经在预研机器上测试OK,于是不停地检查配置文件,查看日志,希望找到原因,在日志中也发现一些类似的错误,但显示的不是3秒而是30秒:
ProcessClusterEventTimeoutException[failed to process cluster event (put-mapping [fluentd]) within 30s]
at org.elasticsearch.cluster.service.InternalClusterService$2$1.run(InternalClusterService.java:349)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
2017-02-17 03:25:01 +0000 [warn]: Could not push logs to Elasticsearch, resetting connection and trying again. read timeout reached
2017-02-17 03:37:43 +0000 [warn]: temporarily failed to flush the buffer. next_retry=2017-02-17 03:35:45 +0000 error_class="Fluent::ElasticsearchOutput::ConnectionFailure" error="Can not reach Elasticsearch cluster ({:host=>\"elasticsearch-logging\", :port=>9200, :scheme=>\"http\"})! read timeout reached" plugin_id="object:3fda30db34f0"
经过多番调整测试无果,百度好久也未找到相关的资料,直到看到这篇文章:
里面讲述了作者公司网络故障导致出现了类似的问题,让我不禁也在想:难道我这里也是网络的问题?有这个疑惑是因为我用命令查看 elasticsearch 集群 api 信息时老是要卡好几秒,偶尔也会超时。
curl http://172.20.32.131:8080/api/v1/proxy/namespaces/kube-system/services/elasticsearch-logging/
{
"name" : "Rose",
"cluster_name" : "kubernetes-logging",
"cluster_uuid" : "B3SopPDKTDCUfmYFD9OwOA",
"version" : {
"number" : "2.4.1",
"build_hash" : "c67dc32e24162035d18d6fe1e952c4cbcbe79d16",
"build_timestamp" : "2016-09-27T18:57:55Z",
"build_snapshot" : false,
"lucene_version" : "5.5.2"
},
"tagline" : "You Know, for Search"
}
这里的 172.20.32.131 是我的 K8S 集群 master,是 v1.4.0 的版本,我的 docker 是安装的 1.12.3 的版本,下面看看 fluentd 日志抓取守护进程的分布:
kubectl get pod --namespace=kube-system -o=wide | grep elastic
elasticsearch-fluentd.1.20-5ypry 1/1 Running 0 9h 192.168.38.11 es-126
elasticsearch-fluentd.1.20-850hr 1/1 Running 0 9h 192.168.37.12 es-122
elasticsearch-fluentd.1.20-8v79v 1/1 Running 0 9h 192.168.40.31 es-125
elasticsearch-fluentd.1.20-c07ln 1/1 Running 0 9h 192.168.34.3 es-134
elasticsearch-fluentd.1.20-dvi10 1/1 Running 0 9h 192.168.47.7 es-124
elasticsearch-fluentd.1.20-ode57 1/1 Running 0 9h 192.168.45.1 es-123
elasticsearch-fluentd.1.20-q5af9 1/1 Running 0 9h 192.168.44.4 es-128
elasticsearch-fluentd.1.20-t70cz 1/1 Running 0 9h 192.168.32.4 es-131
elasticsearch-kibana.4.5-3fxus 1/1 Running 0 9h 192.168.37.13 es-123
elasticsearch-logging.v2.4.1-gvirk 1/1 Running 0 9h 192.168.37.11 es-123
elasticsearch-logging.v2.4.1-n52st 1/1 Running 0 9h 192.168.37.5 es-123
可以看到进程一切正常,那么看看 weave 网络:
kubectl get pod --namespace=kube-system -o=wide | grep weave | grep 172.20.32.123
weave-net-9rr8v 2/2 Running 0 4d 172.20.32.123 es-123
也是一切正常的,真是很奇葩啊!不管了,换一台机器试试,于是我将 elasticSearch 和 kibana 由 172.20.32.123 换到了 172.20.32.122,发现一切正常了,真是哭笑不得啊,难道还真是网络哪里有问题呢?后来据同事反映,这台123的机器前几天无缘无故突然掉出集群,而且重新加入 weave 始终报异常,具体原因也没有找到,这几天才进行了重装。
问题总结
出现这种超时的问题,排除配置错误的情况下,要尽可能考虑网络的问题,多实验,最初我还考虑了是不是日志太多,30秒不够,需要在哪里调整一下超时的参数,后来把容器的日志全部清除后依然超时,才知道这个参数设置了也没有意义,何况还不知道在哪里设置。这也与我刚接触 elasticSearch 有关系,也许别人根本不会出现这种问题。本人在此记录一下,希望有人在碰到同样的问题可以得到一点启发。
配置文件
最后,分享一下我的配置文件供参考,我的镜像均来自谷歌的 Docker Registry
elasticsearch-service.yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "elasticsearch"
spec:
type: NodePort
ports:
- port: 9200
protocol: TCP
targetPort: db
nodePort: 32105
selector:
k8s-app: elasticsearch-logging
elasticsearch-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: elasticsearch-logging.v2.4.1
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
version: v2.4.1
kubernetes.io/cluster-service: "true"
spec:
replicas: 2
selector:
k8s-app: elasticsearch-logging
version: v2.4.1
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v2.4.1
kubernetes.io/cluster-service: "true"
spec:
nodeSelector:
kubernetes.io/hostname: es-122
containers:
- image: google_containers/elasticsearch:v2.4.1
name: elasticsearch-logging
resources:
limits:
cpu: 100m
#memory: 400Mi
requests:
cpu: 100m
#memory: 200Mi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
env:
- name: TZ
value: "Asia/Shanghai"
volumeMounts:
- name: es-persistent-storage
mountPath: /data
volumes:
- name: es-persistent-storage
hostPath:
path: /home/docker/elasticsearch/data
fluentd-daemonset.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: elasticsearch-fluentd.1.20
namespace: kube-system
labels:
k8s-app: elasticsearch-fluentd
spec:
template:
metadata:
labels:
k8s-app: elasticsearch-fluentd
spec:
containers:
- name: elasticsearch-fluentd
image: google_containers/fluentd-elasticsearch:1.20
resources:
limits:
cpu: 100m
#memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
readOnly: false
- name: realcontainers
mountPath: /home/docker_mnt/containers
readOnly: false
env:
- name: TZ
value: "Asia/Shanghai"
- name: KUBERNETES_URL
value: "http://172.20.32.131:8080/api"
- name: ELASTICSEARCH_HOST
value: elasticsearch-logging
- name: ELASTICSEARCH_PORT
value: "9200"
- name: FLUENTD_FLUSH_INTERVAL
value: "60s"
volumes:
- name: varlog
hostPath:
path: /var/log
- name: containers
hostPath:
path: /var/lib/docker/containers
- name: realcontainers
hostPath:
path: /home/docker_mnt/containers
kibana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-kibana
namespace: kube-system
labels:
k8s-app: elasticsearch-kibana
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "kibana"
spec:
type: NodePort
ports:
- port: 5601
protocol: TCP
targetPort: ui
nodePort: 32106
selector:
k8s-app: elasticsearch-kibana
kibana-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: elasticsearch-kibana.4.5
namespace: kube-system
labels:
k8s-app: elasticsearch-kibana
version: v4.5
kubernetes.io/cluster-service: "true"
spec:
replicas: 1
selector:
k8s-app: elasticsearch-kibana
version: v4.5
template:
metadata:
labels:
k8s-app: elasticsearch-kibana
version: v4.5
kubernetes.io/cluster-service: "true"
spec:
nodeSelector:
kubernetes.io/hostname: es-122
containers:
- image: kibana:4.5
name: kibana
resources:
limits:
cpu: 100m
#memory: 400Mi
requests:
cpu: 100m
#memory: 200Mi
ports:
- containerPort: 5601
name: ui
protocol: TCP
env:
- name: TZ
value: "Asia/Shanghai"
- name: ELASTICSEARCH_URL
value: http://172.20.32.131:32105/
清除 K8S 集群所有容器的日志
for i in `find /var/lib/docker/containers -name "*.log"`; do cat /dev/null >$i; done
结语
elasticsearch 这款开源的优秀的搜索引擎工具的确值得深入的学习,填补自己在搜索引擎这一块的空白,这篇文章只是一个起点,加油!